

")





私が大学院でとっているIndividual ResearchおよびBusiness Research Analysisクラスでは、IBMのSPSSを使って分析をしているのですが、あまりサクサク動かないと言うこともあり、R言語とRStudioで勉強を進めています。個人的には、R言語で行った方が、結果がすぐに出てくるので、精神衛生上こちらの方が分析を進めやすいです。
自分の備忘の意味も含めて、どのように行ったかをまとめます。
R言語とRStudioのインストール手順はこちらの「 R と R Studioのインストール – Qiita」をご覧いただければと思います。
重回帰分析とは
重回帰分析はある複数の要素がどの程度他の要素に影響を与えるのかを検証するために役立つ分析方法です。
誤解を恐れずに言えば、「エクササイズ」、「肥満度」、「食事量」と言うそれぞれの要素があったとして、「エクササイズ」と「食事量」はそれぞれどの程度「肥満度」に影響を与えるのかを数値で検証します。また、同時にその分析が、どの程度その結果をカバーしているのか、エラー率はどれぐらいなのかを表します。
僕は現在あるバンコクである意識調査をしていますが、どういった要素がある製品を使用(購入)することにつながるのかといった分析をして、どういったセグメントの人にその製品を働きかけていくのかといったマーケティングのアプローチにこの分析を部分的に使うことができます。
データの準備
今回は意識調査をするために下記の要素があったとします。
- Factor1(質問4つ)
- F1-1
- F1-2
- F1-3
- F1-4
- Factor2(質問3つ)
- F2-1
- F2-2
- F3-3
- Factor3(質問5つ)
- F3-1
- F3-2
- F3-3
- F3-4
- F3-5
まずは、データを読み込んでいきます。
# まずはデータを読み込む
dat
グループ化
各ファクターの調査をしたいので、各ファクターの質問を単純に足して質問数で割り、平均値を出してグルーピングします。
#グルーピングする
dat$F1
クロンバックα信頼係数の計測
次に各要素の信頼性をチェックしておきます。こちらは前回の記事である、「R言語によるクロンバックα信頼性係数の計測」の記事を別途ご覧ください。
#クロンバックα信頼性係数の計測
library(psych,ltm)
cronbach.alpha(dat[,dat$F1])
cronbach.alpha(dat[,dat$F2])
cronbach.alpha(dat[,dat$F3])
相関行列図の作成
次に相関行列の図を作って見ます。また、関数の一部を取り出すにはSubset関数を使って行います。今回は、各質問のデータは使いませんので、subsetでF1からF3のみを抽出して行います。
install.packages("corrplot")
library(corrplot)
#SubsetでF1からF3のみを抽出
a
すると、下記のようなデータを抽出できました。
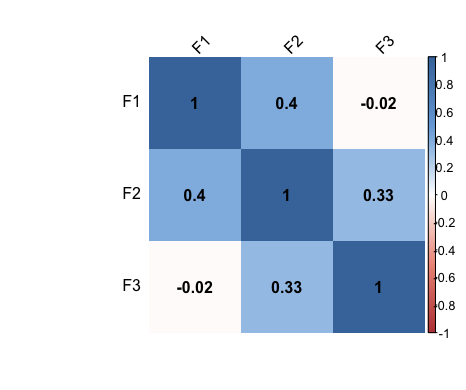
ちなみに、手元にあるデータで変数を増やして出力して見ます。


このように、その値と他の相関が直感的にわかるようになります。
重回帰分析(Multiple Linear Regression Analysis)
重回帰分析(Multiple Linear Regression Analysis)をする前に、まずはそのモデルを確認して見ます。
packages.install("igraph")
library(igraph)
plot(graph(c("F1","F3", "F2","F3")), vertex.size = 50)
今回はこんな感じのモデルです。

信頼性をチェックし終わったら、次にそのモデルに沿って重回帰分析(Multiple Linear Regression Analysis)をしていきます。
fit
lm(F3 ~ F1 + F2, data=dat)だけでもいいのですが、R Squareなどの値が出ません。summaryで挟んであげることによって、p-valueやt-value等も出ますので、どの要素がその要素に影響するのかががわかるようになります。
分散拡大係数(VIF)の計測
また、分散拡大係数 (VIF)も同時に調べて見ます。分散拡大係数が5以下であれば良いって先生が言っていたけれども、ちゃんと意味を知らないとなと。
install.packages("car")
library(car)
vif(fit)
## 以下結果
F1 F2
1.19451 1.19451





{kind=link}